

Time kills startups. Solving problems creates businesses. Startups are in a race to solve problems before running out of time.
Challenging problems with a high difficulty level can take time to solve. And when markets want a problem solved, the more difficult the problem, the more valuable the solution. Solving challenging problems can be rewarding. If you don’t run out of time.
Point Focal was created to capture and make sense of high-value, difficult-to-access alternative fintech data. Selecting data is a critical input to building portfolio analytics. The solution’s entire worth is data dependent. Selection is particularly daunting when starting from a blank canvas of nothingness. Not a single column, row, or data element. A challenging problem to solve.
Earnings matter. Demand for future earnings information is universal. Everyone, buy-side, sell-side, institutional, and retail, want high quality information about future earnings expectations. Every portfolio manager (PM), trader, analyst, and individual with a pricing model - fundamental, quantitative, and quantamental - requires earnings information as an input.
A premise of ours is if we can identify alternative earnings data with more meaningful and verifiable value than traditional earnings data, we can help everyone who cares about earnings. In this sense ‘alternative’ means different from Wall Street. And ‘help’ means automatically overlaying quantitative earnings analytics on portfolios.
Estimize is a 10-year-old fintech firm with a crowd-sourced platform of earnings estimates. Their estimate sample is larger than Wall Street and comes from a more diverse buy-side, sell-side, academic, and practitioner community. This is the ‘crowd’ in crowd-sourced. And while the term can cause some to recoil, it shouldn’t. Especially for those who appreciate that crowds, in many contexts, tend to have more wisdom than single or central institutions. The wisdom of this crowd is not unique. Estimize estimates are quantitatively proven to be more accurate than traditional Wall Street sell-side estimates.
Over eight years of data history, relative to Wall Street, Estimize has produced more than twice the number of estimates per earnings release on average with wider estimate dispersion and three times the average number of revisions per estimate. The Estimize consensus has been closer to actual reported results 70% of the time compared to legacy sell-side only estimate data sets.
So why is everyone looking at Wall Street estimates when there is a higher quality source of future earnings? Historical inertia. In other words, my least favorite answer to the “Why do we do it like that?” question. “Because we’ve always done it like that.”
Spoiler alert: Wall Street has a bias. A bias so obvious it is taken for granted. The same investment banks that take companies public are publishing estimates on their future earnings. As can be observed in the data, it is more difficult for companies to beat Estimize estimates than to beat Wall Street estimates. A non-trivial question arises from further exploration: if a company never misses Wall Street estimates, are Wall Street estimates valuable?
Higher quality earnings estimates mean better information, improved model accuracy, and opportunities to improve performance and risk management. We wanted to bring Estimize content to the asset management community.
From what we could tell, only the most sophisticated, quantitative managers were using Estimize data to increase alpha. We believed this was due to two reasons:
The difficulty level of integrating an end-to-end Estimize workflow into an investment process.
Lack of awareness.
It is not easy for an asset manager to capture, transform, and contextualize Estimize data across their portfolios at scale. It is impossible if you don’t know Estimize exists. We considered these problems to solve. This is our Estimize story.
We prioritized Estimize. This was the first data set beyond market, reference, and free1 data that we pursued. In the end, our earnings premise was simple. Solving it has been incredibly challenging.
Our pursuit started with a cold email. I wrote Leigh Drogen, founder of Estimize, twice over a few weeks. Leigh responded, joined a call with me, and appreciated what we wanted to accomplish. Leigh empathized with the challenges of building a fintech data and analytics product. He is a believer in and a supporter of entrepreneurial efforts in the space. From experience, I know there are many firms unwilling to work with a bootstrapped startup. This is both understandable and exhausting. I appreciate the cost-benefit analysis of such decisions from established firms. However, I also believe if there is minimal cost, low risk, and asymmetric upside to the established firm, there is value in supporting aspiring businesses. Sometimes filters should be applied to cost-benefit analyses. Leigh’s willingness to work with Point Focal is something I am excited to pay forward to another firm in the future.
We began exploring Estimize data with great enthusiasm. The beauty of Estimize is its simplicity: better estimates. Yet as we analyzed Wall Street estimates, Estimize consensus estimates, actual earnings per share, revenue, estimate counts, weighted and unweighted consensus2, contributor information, and other metrics, we discovered there was a lot to learn. And as we learned, we began to understand that the implications of better estimates were greater than we initially thought.
Our first goal was to create an institutional workflow making it easy for PMs and traders to consume and understand Estimize data with descriptive earnings analytics overlaid on their portfolios. Occasionally we would get excited about something else we could3 do with Estimize data - quantitative models, contributor analytics, company KPIs - there were lots of possibilities. But each time we veered from our initial vision we set ourselves back. The art of building a business is often choosing what not to do. Time kills startups. Every delay a silent tick of the demise clock.
With initial views created, we began telling the Estimize story in product demos. It is a fantastic story, and we were surprised by how many asset managers were unfamiliar with, and amazed by, Estimize. Yes, the estimates are more accurate than Wall Street. Yes, we have the history. Yes, we can show you trends and the latest consensus and revisions for your upcoming releases.


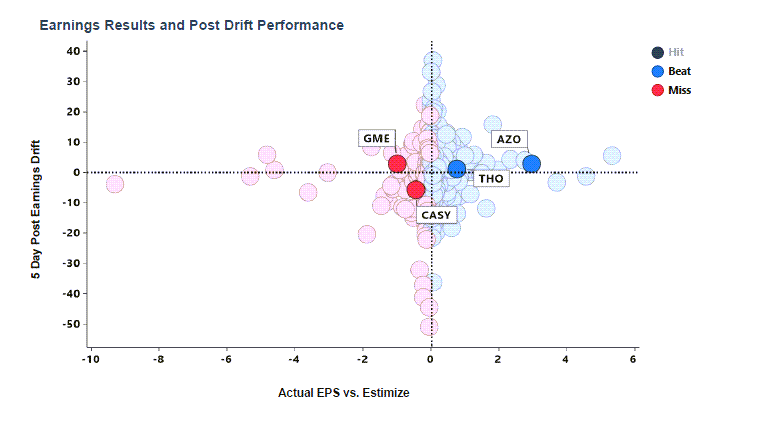
Our views created curiosity and interest, but traders wanted to understand how to incorporate Estimize data into their workflows. This produced many discussions that led toward an answer still being shaped. The process was informative and caused us to shift analytic views from descriptive to proscriptive. We created analytics illustrating what happened after historical earnings releases to help inform current earnings releases. The historical future. Because time is relative. Specifically, we created post-earnings drift views displaying return curves of stock performance following earnings releases. We were moving from interesting to useful.

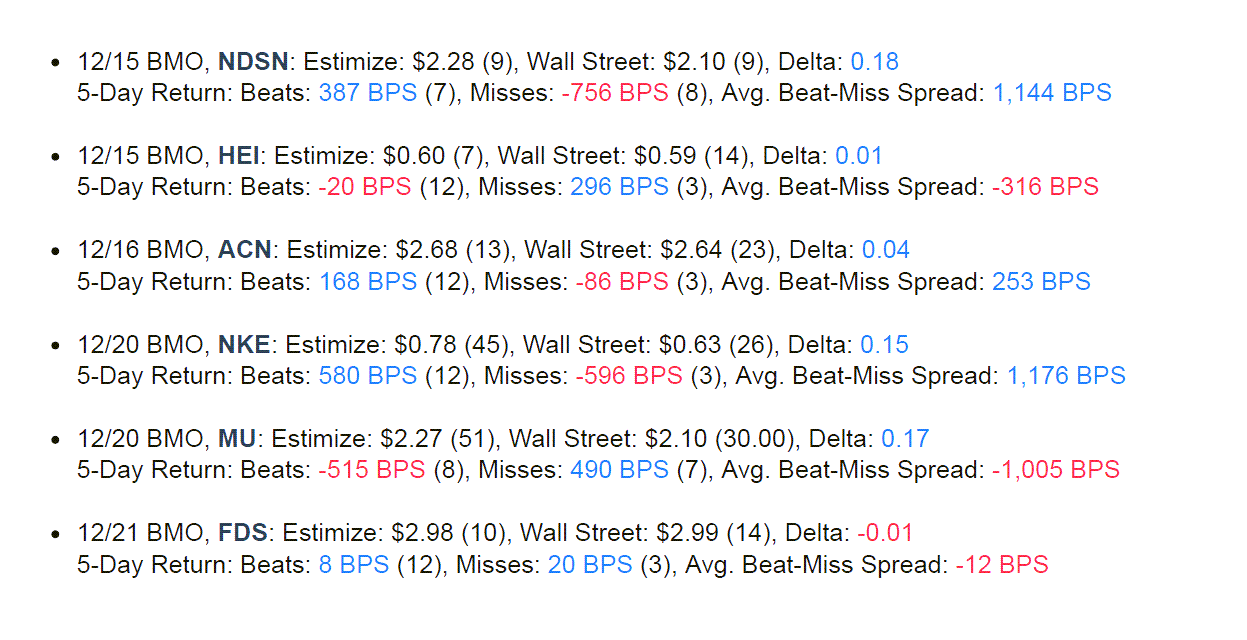
Over time we enhanced our views to display significant post-earnings drift detail. One to twenty-day performance metrics in the post-earnings drift period were aggregated by releases that beat and missed Estimize and Wall Street estimates. This is valuable information previously inaccessible to portfolio managers in the aftermath of an earnings surprise.
Changing trading desk conversations from gut-feelings to quantitative analytics is a mind shift that does not happen overnight. Change resonates most with those unconstrained by primitive “we do it this way because we’ve always done it this way” thinking. We want to work with those who want to change. To find them, we are continuously refining how we communicate the value proposition of having superior estimates leading up to and immediately following earnings releases.

Another reason we love the Estimize story is the nature of earnings seasons. Four times a year, portfolios enter and exit earnings season. As we continued to explore and create Estimize value, we began to understand how the data can be useful in pre-earnings, through-earnings, and post-earnings time frames.
Ahead of earnings releases the delta between Estimize and Wall Street estimates can be tracked. The Estimize platform is far more dynamic than the traditional sell-side process, enabling tracking of new estimates, revisions and estimate dispersion leading into earnings events. Our analytics are informed by how rapidly Estimize estimates change, how dramatically they change, and how close to earnings releases such changes occur.
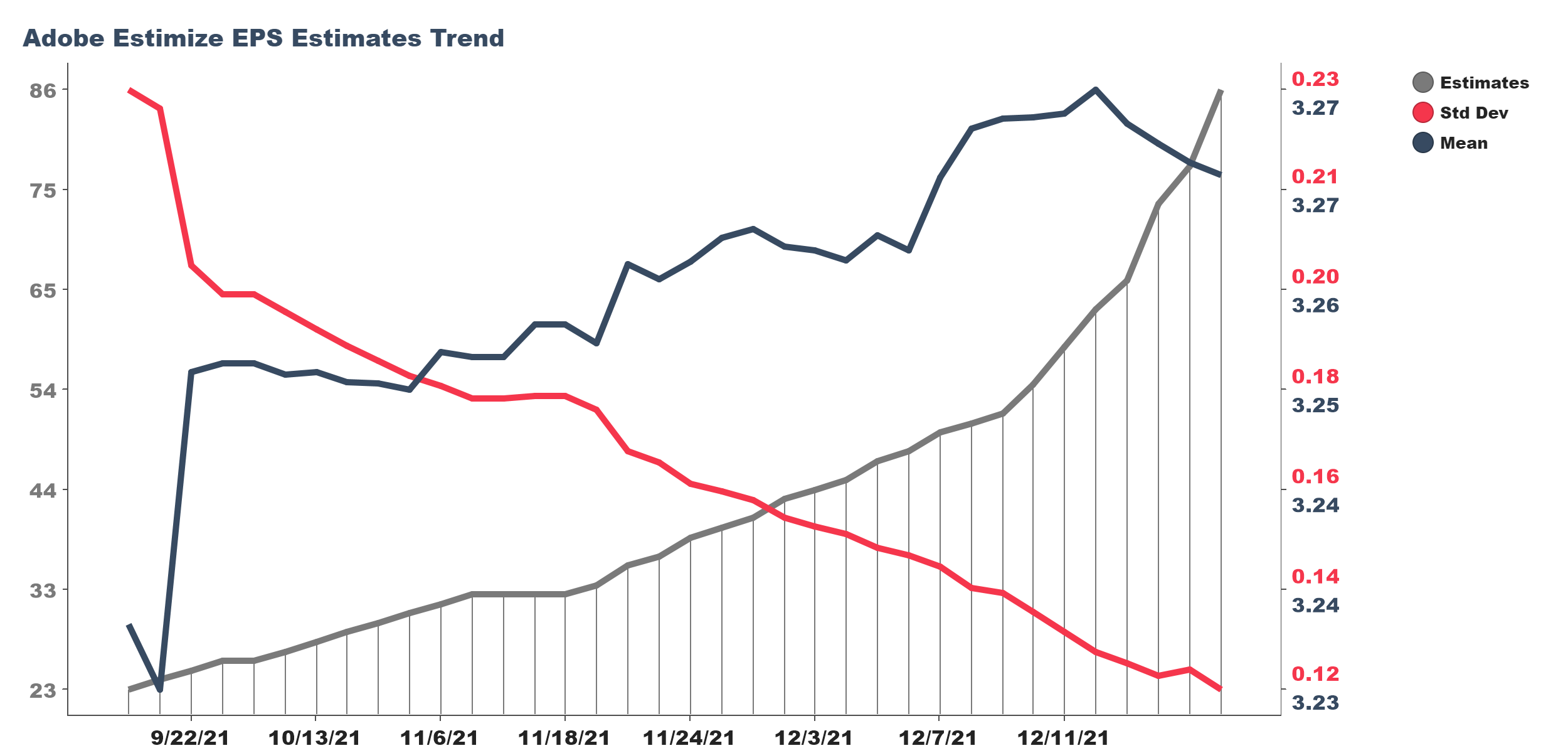
Some of the analysis is counter intuitive. For instance, how should one interpret the scenario where Estimize is expecting a higher earnings release than Wall Street? Does this mean the company is likely to report higher earnings than Wall Street is expecting? Yes. Does it also mean the true reflection of earnings is a more difficult standard for the company to meet and that the company may therefore struggle through earnings season? Also, yes.
Answering these questions led us to the Estimize Post-Earnings Drift quantitative model. In fact, we had begun building it before we knew what it was.
The original Estimize post-earnings drift event study was published in 2018 and explored “the relationship between the post-earnings EPS surprise and the cumulative residual returns in the days following the event”. The study’s conclusions are as follows:
There is a positive cumulative residual return when the EPS surprise is positive and vice versa.
Negative earnings surprises tend to produce a larger negative return than positive surprises.
After day one, negative earnings surprises show a reversal in cumulative residual returns from negative to positive.
Estimize EPS deltas produced more alpha following an event than the Wall Street EPS deltas.
Sector analysis showed most sectors produced strong alpha except for Consumer Staples, Healthcare and Utilities.
Market Cap analysis showed that Small and Mid-Cap stocks produced the strongest alpha.
For the quantitatively inclined, here is a link to the original Estimize post-earnings event study in GitHub.
A more concise summary of the study: Estimize data has alpha. With this knowledge we set out to replicate, optimize and productize the post-earnings drift model. Estimize has been quite helpful along the way and even validated from their experience that there is a market for quantitative modeling as a service solutions.
We have unwound and rewound the event study. First locally in R. Now in AWS using Python. We failed multiple times trying to implement the model. But we believed in our premise, in the value of the data, and in the insight we knew it could produce. We sought and received all the help we could and eventually implemented the model successfully. Indeed, there is alpha in the model. But damned if we knew how to calculate cumulative residual return. We are solving that equation now as part of the performance attribution views we are layering onto the model.

Processing the model from Q1-2018 through Q3-2021 resulted in analyzing 4,500 earnings releases across 1,400 symbols. The model classifies every release into one of ten quantiles based on the statistical significance of the earnings beat or miss. Importantly, earnings yield normalized EPS results are used in the classification.
The basic premise of the model is that the largest positive earnings surprises (quantile 10) outperform the largest negative earnings surprises (quantile 1). Simulating a long-quantile-10, short-quantile-1 strategy, results show an average post earnings drift performance delta between quantiles 10 and 1 of 101 basis points on day one, increasing to 217 basis points on day twenty. The median performance delta between the same top and bottom quantiles are 64 bps and 186 bps, respectively.

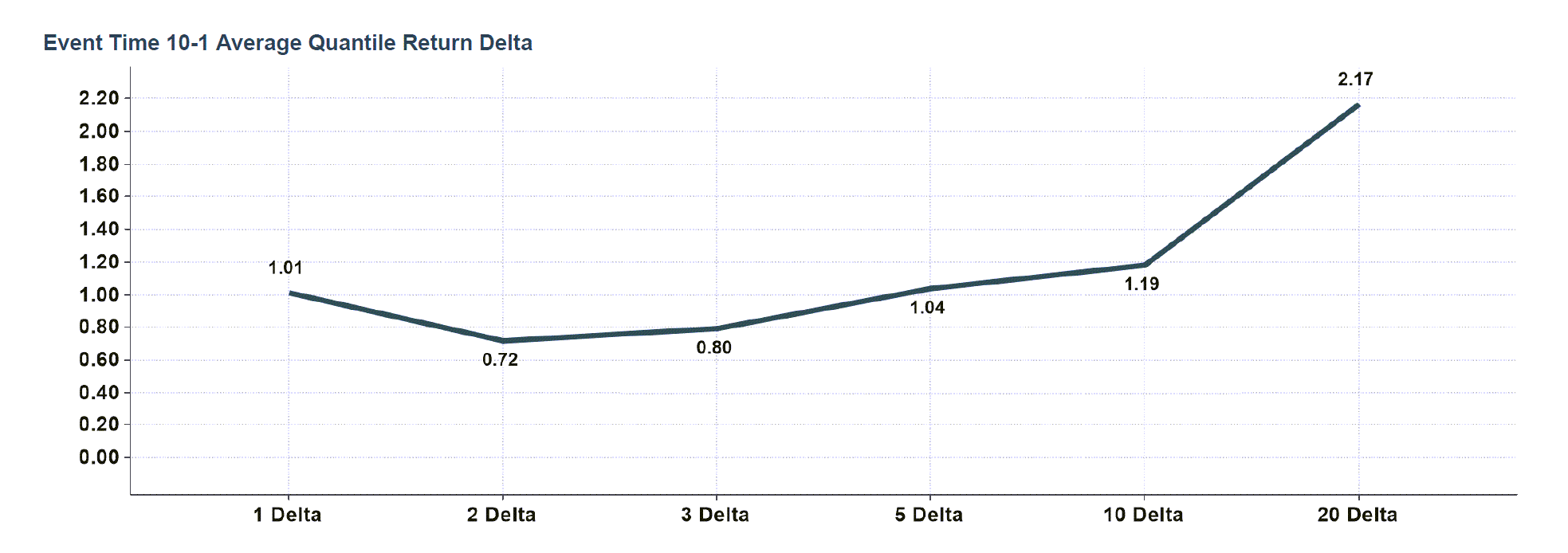
Of market caps, small caps realized the strongest performance. Our sector analysis is in process, and we are considering weighting the results. One challenge is the sector classification information available to us is a distant second in popularity and use. GICS4, the most common sector classification scheme, is laughably expensive. We look forward to paying for it as our business matures or identifying a superior classification system.
A lot happened in the world between the start and end dates of our analysis. COVID surfaced. Trump was banished from Twitter. And we won our first customer. The VIX CBOE Volatility Index spanned a low of 9 to a high of 82. We analyzed many cuts of the data including pre-and-post-COVID periods, low and high volatility periods, and more. We seek to identify optimal post-earnings drift model conditions and make various scenarios available for analysis.
How an asset manager uses Estimize information depends on where they exist on the discretionary-to-systematic strategy continuum. Our goal is to deliver end-to-end analytics that deliver everything from descriptive context to quantitative signals. While we have been building the Estimize post-earnings drift model, we have also been rearchitecting our analytics stack from top (ingestion) to bottom (delivery). In so doing, we are creating the ability to automatically process the Estimize model daily for custom portfolios. We will generate and surface the resulting signals at the right time to the right people. And we will provide thorough performance attribution for portfolios and their benchmarks.
Most exciting is the fact that post-earnings drift is only one leg of a three-legged Estimize quant model stool. The other two legs are pre-earnings drift and through-earnings drift. By analyzing Estimize revisions and Estimize to Wall Street deltas during the pre-earnings period, we can introduce risk management insight. The through-earnings model bridges pre-and-post earnings models adding quantitative metrics from the interval one-day-before earnings to one-day-after earnings. Estimize enables us to deliver a year-round, continuous stream of earnings analytics.
We are fortunate to also be partnered with Brain Company. We are working with their back-testing engine to integrate model results with our Brain News Sentiment Indicator analytics. But we can also use it with non-Brain content like Estimize. This means we can deliver rolling quantitative model results including cumulative return, annualized return, Sharpe ratio, volatility, max drawdown, time to recovery, and more. The end-to-end quantitative model as a service offering is becoming tangible. I will provide a deep dive into our Brain partnership and their NLP (Natural Language Processing) driven alternative data in a future Focus Signal post.
Envisioning the systematic processing of all three Estimize earnings models across custom portfolios year-round, with signal generation and performance attribution throughout, gives one an idea of the magnitude of this challenge. It is what excites me about delivering value in this space. It is why I’m writing Focus Signal.
Productizing Estimize analytics at scale, in full, is still a solution being realized through our execution. While we are confident, we are also humbly aware that time, the great startup killer, is our biggest enemy. Solving this earnings challenge is not for everyone. This earnings solution is not for everyone. But for PMs, traders, and analysts who want to monetize data, it is a challenge worth solving.
The free data set is another story for another Focus Signal post.
The plural of consensus is consensus.
I was once asked by an EVP if the reason I used italics was because I thought we were in the second grade. Now I use italics to emphasize one point and remind me of another.
GICS is the Global Industry Classification Standard developed by MSCI (Morgan Stanley Capital International) and Standard & Poor’s.